Baseline models & k-Nearest Neighbours
Contents
3. Baseline models & k-Nearest Neighbours#
3.1. Lecture Learning Objectives#
Use
DummyClassifierandDummyRegressoras baselines for machine learning problems.Explain the notion of similarity-based algorithms .
Broadly describe how KNNs use distances.
Discuss the effect of using a small/large value of the hyperparameter \(K\) when using the KNN algorithm
Describe the problem of the curse of dimensionality.
import pandas as pd
import numpy as np
from sklearn.model_selection import cross_validate, train_test_split
from sklearn.dummy import DummyClassifier
from sklearn.dummy import DummyRegressor
from sklearn.tree import DecisionTreeClassifier
import altair as alt
from sklearn.metrics.pairwise import euclidean_distances
from sklearn.neighbors import NearestNeighbors
from sklearn.neighbors import KNeighborsClassifier
import warnings
warnings.filterwarnings('ignore')
import os
import sys
sys.path.append(os.path.join(os.path.abspath("."), "code"))
from plotting_functions import *
from utils import *
3.2. Five Minute Recap/ Lightning Questions#
What are the 4 types of data/splits that we discussed last class?
What is the “Golden Rule of Machine Learning”?
What do we use to split our data?
What is overfitting and underfitting?
3.2.1. Some lingering questions#
Are decision trees the most basic model?
What other models can we build?
3.3. Baseline Models#
We saw in the last 2 lectures how to build decision tree models which are based on rules (if-else statements), but how can we be sure that these models are doing a good job besides just accuracy?
Back in high school in chemistry or biology, we’ve all likely seen and heard of the “control group” where we have an experimental group, does not receive any experimental treatment. This control group increases the reliability of the results, often through a comparison between control measurements and the other measurements.
Our baseline model is something like a control group in the sense that it provides a way to sanity-check your machine learning model. We make baseline models not to use for prediction purposes, but as a reference point when we are building other more sophisticated models.
So what is a baseline model then?
Baseline: A simple machine learning algorithm based on simple rules of thumb. For example,
most frequent baseline: always predicts the most frequent label in the training set.
3.3.1. Dummy Classifier#
We are going to build a most frequent baseline model which always predicts the most frequently labelled in the training set.
# import dataset
voting_df = pd.read_csv('data/cities_USA.csv', index_col=0)
voting_df
# feature table
X = voting_df.drop(columns='vote')
# the target variable
y = voting_df[['vote']]
# split into train and test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=123)
We build our model, in the same way as we built a decision tree model but this time using DummyClassifier.
Since we are using a “most frequent” baseline model, we specify the argument strategy as "most_frequent"
There are other options that you you read about in the sklearn documentation but you just need to know most_frequent for now.
# create a dummy classifier
dummy_clf = DummyClassifier(strategy="most_frequent")
In the last lecture, we stated that it’s at this point that we would usually perform cross-validation to evaluate the model performance.
With Dummy Classifiers, we won’t need to because we are not hyperparameter tuning. We are using this just to get a base training score.
dummy_clf.fit(X_train, y_train)
dummy_clf.score(X_train, y_train)
If we see what our model predicts on the feature table for our training split X_train, our model will predict the most frequent class from our training data.
y_train.value_counts()
dummy_clf.predict(X_train)
We can also now take the test score.
dummy_clf.score(X_test, y_test)
Here is a good example of when we occasionally have test scores better than the training scores.
In this case, it’s higher because our test split has a higher proportion of observations that are of class blue and so more of them will be predicted correctly.
Now if we build a decision tree, we can compare it to the baseline model score.
Here we use cross-validation to score the model although we are not tuning any hyperparameters. It is general a good idea to get into the habit of doing this for all models except baseline/dummy models, because the split can influence the model score (this is true to a much lesser extent for baseline models)
# create a decision tree classifier
dt_clf = DecisionTreeClassifier(random_state=42)
# cross validate the decision tree classifier
scores = cross_validate(dt_clf, X_train, y_train, cv=10, return_train_score=True)
# mean score
pd.DataFrame(scores).mean()[-2:]
dt_clf.fit(X_train, y_train)
dt_clf.score(X_test, y_test)
We can see that our decision tree is doing better than a model build on this simple “most frequently” occurring model. This makes us trust our model a little more and we know that it has identified some structure in the data that is more complicated than simply predicting the most common label. This is especially important if we have an unbalanced training data set with much more of one label than of another, but there are also more sophisticated strategies to handle that situation, which we will discuss later.
3.3.2. Dummy Regressor#
For a Dummy regressor, the same principles can be applied but by using different strategies.
“mean”, “median”, “quantile”, “constant”
The one we are going to become most familiar with is:
Average (mean) target value: always predicts the mean of the training set.
house_df = pd.read_csv("data/kc_house_data.csv")
house_df = house_df.drop(columns=["id", "date"])
house_df
Let get our X and y objects and split our data.
X = house_df.drop(columns=["price"])
y = house_df["price"]
We still need to make sure we split our data with baseline models.
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=123)
we need to import DummyRegressor and construct our model.
We specify strategy="mean" however this is the default value so technically we don’t need to specify this.
We train our model and again, it’s not needed to cross-validate for this type of algorithm.
dummy_reg = DummyRegressor(strategy="mean")
dummy_reg.fit(X_train,y_train)
If we predict on our training data, we see it’s making the same prediction for each observation.
dummy_reg.predict(X_train)
if we compare the mean value of the target, we see that our model is simply predicting the average of the training data which is exactly what we expect.
y_train.mean()
How well does it do?
dummy_reg.score(X_train, y_train)
We get an \(R^2\) value of 0.0.
When a model has an \(R^2\)=0 that means that the model is doing no better than a model that using the mean which is exactly the case here.
Looking at the test score we see that our model get’s a slightly negative value, which means that it is doing a little worse than constantly predicting the mean of the test data.
dummy_reg.score(X_test, y_test)
3.4. Let’s Practice#
1. Below we have the output of y_train.value_counts()
Position
Forward 13
Defense 7
Goalie 2
dtype: int64
In this scenario, what would a DummyClassifier(strategy='most_frequent') model predict on the following observation:
No. Age Height Weight Experience Salary
1 83 34 191 210 11 3200000.0
2. When using a regression model, which of the following is not a possible return value from .score(X,y) ?
a) 0.0
b) 1.0
c) -0.1
d) 1.5
3. Below are the values for y that were used to train DummyRegressor(strategy='mean'):
Grade
0 75
1 80
2 90
3 95
4 85
dtype: int64
What value will the model predict for every example?
Solutions!
Forwardd) 1.5
85
3.5. Similarity/analogy-based models#
Let’s switch topics from baseline models and talked about the concept of similarity based models.
Suppose you are given the following training images with the corresponding actor’s name as the label. Then we are given an unseen test images of the same actors but from different angles and are asked to label a given test example.
An intuitive way to classify the test example is by finding the most “similar” example from the training images and use that label for the test example.

3.5.1. Example:#
Suppose we are given many images and their labels.
X = set of pictures
y = names associated with those pictures.
Then we are given a new unseen test example, a picture in this particular case.

We want to find out the label for this new test picture.
Naturally, we would try and find the most similar picture in our training set and using the label of the most similar picture as the label of this new test example.
That’s the basic idea behind similarity/analogy-based algorithms.
This is different from Decision trees, where we tried to learn a set of rules/conditions to label observations correctly.


3.6. Terminology#
In analogy-based algorithms, our goal is to come up with a way to find similarities between examples. “similarity” is a bit ambiguous so we need some terminology.
data: think of observations (rows) as points in a high dimensional space.
Each feature: Additional dimension.
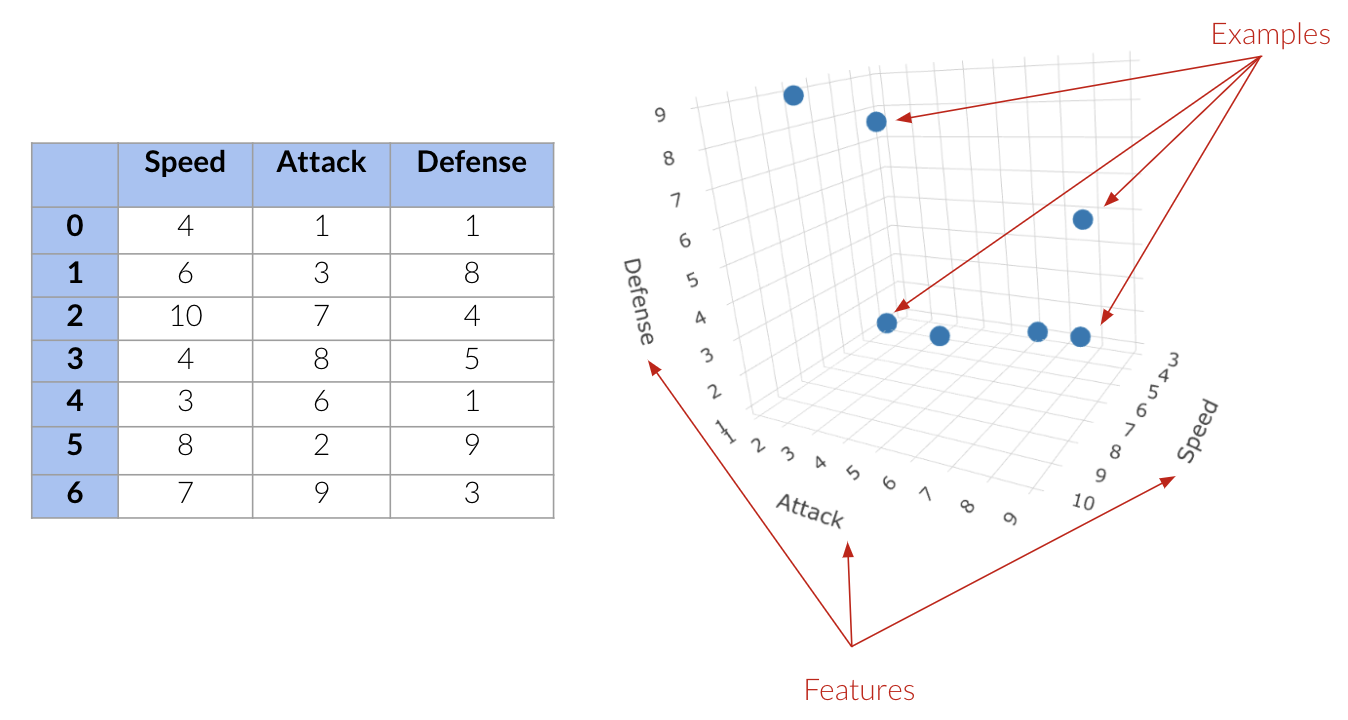
Above we have:
Three features; speed attack and defense.
7 points in this three-dimensional space.
Let’s go back to our Canada/USA cities dataset.
cities_df = pd.read_csv("data/canada_usa_cities.csv")
cities_train_df, cities_test_df = train_test_split(cities_df, test_size=0.2, random_state=123)
cities_train_df
We have 2 features, so 2 dimensions (longitude and latitude) and 167 points.
Visualizing this in 2 dimensions gives us the following:
cities_viz = alt.Chart(cities_train_df).mark_circle(size=20, opacity=0.6).encode(
alt.X('longitude:Q', scale=alt.Scale(domain=[-140, -40])),
alt.Y('latitude:Q', scale=alt.Scale(domain=[20, 60])),
alt.Color('country:N', scale=alt.Scale(domain=['Canada', 'USA'],
range=['red', 'blue']))
)
cities_viz
What about the housing training dataset we saw?
house_df = pd.read_csv("data/kc_house_data.csv")
house_df = house_df.drop(columns=["id", "date"])
X = house_df.drop(columns=["price"])
y = house_df["price"]
house_X_train, house_X_test, house_y_train, house_y_test = train_test_split(
X, y, test_size=0.2, random_state=123)
house_X_train
Notice a problem?!
We can only visualize data when the dimensions <= 3.
BUT, in ML, we usually deal with high-dimensional problems where examples are hard to visualize. High dimensional = 100s or 1000s of dimensions (roughly speaking, it depends on the specific problem at hands and the density of the data).
3.6.1. Feature Vectors#
Feature vector: a vector composed of feature values associated with an example.
An example feature vector from the cities dataset:
cities_train_df.drop(columns=["country"]).iloc[0].to_numpy()
An example feature vector from the housing dataset:
house_X_train.iloc[0].to_numpy()
3.7. Distance#
We have our feature vectors, one for each observation, but how we calculate the similarity between these feature vectors?
One way to calculate the similarity between two points in high-dimensional space is by calculating the distance between them.
So, if the distance is higher, that means that the points are less similar and when the distance is smaller, that means that the points are more similar.
3.7.1. Euclidean distance#
There are different ways to calculate distance but we are going to focus on Euclidean distance.
Euclidean distance: Euclidean distance is a measure of the true straight line distance between two points in Euclidean space. (source)
The Euclidean distance between vectors
\(u = <u_1, u_2, \dots, u_n>\) and
\(v = <v_1, v_2, \dots, v_n>\) is defined as:
\(distance(u, v) = \sqrt{\sum_{i =1}^{n} (u_i - v_i)^2}\)
Because that equation can look a bit intimidating, let’s use it in an example, particularly our Canadian/US cities data.
3.7.1.1. Calculating Euclidean distance “by hand”#
cities_train_df
Let’s take 2 points (two feature vectors) from the cities dataset.
two_cities = cities_df.sample(2, random_state=42).drop(columns=["country"])
two_cities
The two sampled points are shown as black circles below.
Our goal is to find how similar these two points are.
cities_viz + alt.Chart(two_cities).mark_circle(size=130, color='black').encode(
alt.X('longitude'),
alt.Y('latitude')
)
First, we subtract these two cities. We are subtracting the city at index 0 from the city at index 1.
two_cities.iloc[1] - two_cities.iloc[0]
Next, we square the differences.
(two_cities.iloc[1] - two_cities.iloc[0])**2
Then we sum up the squared differences.
((two_cities.iloc[1] - two_cities.iloc[0])**2).sum()
And then take the square root of the value.
# To the power of 0.5 is the same as square root
((two_cities.iloc[1] - two_cities.iloc[0])**2).sum()**0.5
We end with a value of 13.3898 which is the distance between the two cities in feature space.
3.7.1.2. Calculating Euclidean distance with sklearn#
That’s more work than we really have time for and since sklearn knows we are very busy people, they have a function that does this for us.
euclidean_distances(two_cities)
When we call this function on our two cities data, it outputs this matrix with four values.
Our first value is the distance between city 0 and itself.
Our second value is the distance between city 0 and city1.
Our third value is the distance between city 1and city 0.
Our fourth value is the distance between city 1 and itself.
As we can see, the distances are symmetric. If we calculate the distance between city 0 and city1, it’s going to have the same value as if we calculated the distance between city 1 and city 0.
This isn’t always the case if we use a different metric to calculate distances.
3.8. Finding the Nearest Neighbour#
Now that we know how to calculate the distance between two points, we can use this metric as a definition for what “most similar” means in our cities data. In this case, we would say that it is the cities that have the shortest distance between them. These are often called the “Nearest Neighbors”.
Let’s find the closest cities to City 0 from our cities_train_df dataframe.
Using euclidean_distances on the entire dataset will calculate the distances from all the cities to all other cities in our dataframe.
dists = euclidean_distances(cities_train_df[["latitude", "longitude"]])
dists
This is going to be of shape 167 by 167 as this was the number of examples in our training portion.
Each row here gives us the distance of that particular city to all other cities in the training data.
dists.shape
pd.DataFrame(dists)
The distance of each city to itself is going to be zero.
If we don’t replace the 0’s on the diagonal with infinity, each city’s most similar city is going to be itself which is not useful.
np.fill_diagonal(dists, np.inf)
pd.DataFrame(dists)
Now let’s look at the distance between city 0 and some other cities.
We can look at city 0 with its respective longitude and latitude values.
cities_train_df.iloc[[0]]
And the distances from city 0 to the other cities in the training dataset.
dists[0]
Remember that our goal is to find the closest example to city 0.
We can find the closest city to city 0 by finding the city with the minimum distance.
np.argmin(dists[0])
The closest city in the training dataset is the city with index 157.
This corresponds to index 96 from the original dataset before shuffling.
cities_train_df.iloc[[157]]
If we look at the longitude and latitude values for the city at index 157 (labelled 96), they look pretty close to those of city 0.
cities_train_df.iloc[[0]]
dists[0][157]
So, in this case, the closest city to city 0 is city 157 and the Euclidean distance between the two cities is 0.184.
3.8.1. Nearest city to a query point#
We can also find the distances to a new “test” or “query” city:
query_point = [[-80, 25]]
dists = euclidean_distances(cities_train_df[["longitude", "latitude"]], query_point)
dists[:10] # Only show the first few observations
We can find the city closest to the query point (-80, 25) using:
np.argmin(dists)
dists[np.argmin(dists)]
So the city at index 147 is the closest point to (-80, 25) with the Euclidean distance between the two equal to 3.838
Instead of doing this manually we can use Sklearn’s NearestNeighbors function to get the closest example and the distance between the query point and the closest example.
nn = NearestNeighbors(n_neighbors=1)
nn.fit(cities_train_df[['longitude', 'latitude']]);
nn.kneighbors([[-80, 25]])
We can also use kneighbors to find the 5 nearest cities in the training split to one of the cities in the test split.
cities_test_X = cities_test_df[['longitude', 'latitude']]
nn = NearestNeighbors(n_neighbors=5)
nn.fit(cities_train_df[['longitude', 'latitude']]);
nn.kneighbors(cities_test_X.iloc[[1]])
On the last line, we need to be careful and make sure that we pass in either a 2D numpy array or a dataframe as our input. This is why we use 2 sets of square brackets with our city above.
3.9. Let’s Practice#
seeds shape sweetness water-content weight fruit_veg
0 1 0 35 84 100 fruit
1 0 0 23 75 120 fruit
2 1 1 15 90 1360 veg
3 1 1 7 96 600 veg
4 0 0 37 80 5 fruit
5 0 0 45 78 40 fruit
6 1 0 27 83 450 veg
7 1 1 18 73 5 veg
8 1 1 32 80 76 veg
9 0 0 40 83 65 fruit
1. Giving the table above and that we are trying to predict if each example is either a fruit or a vegetable, what would be the dimension of feature vectors in this problem?
2. Which of the following would be the feature vector for example 0.
a) array([1, 0, 1, 1, 0, 0, 1, 1, 1, 0])
b) array([fruit, fruit, veg, veg, fruit, fruit, veg, veg, veg, fruit])
c) array([1, 0, 35, 84, 100])
d) array([1, 0, 35, 84, 100, fruit])
3. Given the following 2 feature vectors, what is the Euclidean distance between the following two feature vectors?
u = np.array([5, 0, 22, -11])
v = np.array([-1, 0, 19, -9])
True or False
4. Analogy-based models find examples from the test set that are most similar to the test example we are predicting.
5. Feature vectors can only be of length 3 since we cannot visualize past that.
6. Euclidean distance will always have a positive value.
7. When finding the nearest neighbour in a dataset using kneighbors() from the sklearn library, we must fit the data first.
Solutions!
5 dimensions.
c)
array([1, 0, 35, 84, 100])7
False
False
True
True
3.10. \(k\) -Nearest Neighbours (\(k\)-NNs) Classifier#
Now that we have learned how to find similar examples, can we use this idea in a predictive model?
Yes! The k Nearest Neighbors (kNN) algorithm
This is a fairly simple algorithm that is best understood by example
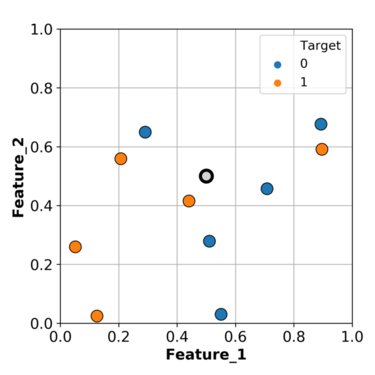
We have two features in our toy example; feature 1 and feature 2.
We have two targets; 0 represented with blue points and 1 represented with orange points.
We want to predict the point in gray.
Based on what we have been doing so far, we can find the closest example (\(k\)=1) to this gray point and use its class as the class for our grey point.
In this particular case, we will predict orange as the class for our query point.
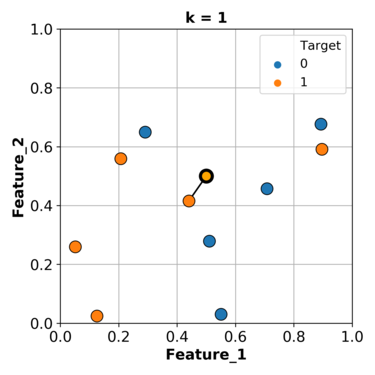
What if we consider more than one nearest example and let them vote on the target of the query example.
Let’s consider the nearest 3 neighbours and let them vote.
Let’s try this with a smaller set of our data and sklearn.
small_train_df = cities_train_df.sample(30, random_state=1223)
small_X_train = small_train_df.drop(columns=["country"])
small_y_train = small_train_df["country"]
one_city = cities_test_df.sample(1, random_state=33)
one_city
chart_knn = alt.Chart(small_train_df).mark_circle().encode(
alt.X('longitude', scale=alt.Scale(domain=[-140, -40])),
alt.Y('latitude', scale=alt.Scale(domain=[20, 60])),
alt.Color('country', scale=alt.Scale(domain=['Canada', 'USA'], range=['red', 'blue'])))
one_city_point = alt.Chart(one_city).mark_point(
shape='triangle-up', size=400, fill='darkgreen', opacity=1).encode(
alt.X('longitude'),
alt.Y('latitude')
)
chart_knn + one_city_point
We want to find the class for this green triangle city.
neigh_clf = KNeighborsClassifier(n_neighbors=1)
neigh_clf.fit(small_X_train, small_y_train)
neigh_clf.predict(one_city.drop(columns=["country"]))
We can set n_neighbors equal to 1 to classify this triangle based on one neighbouring point.
Our prediction here is Canada since the closest point to the green triangle is a city with the class “Canada”.
Now, what if we consider the nearest 3 neighbours?
neigh_clf = KNeighborsClassifier(n_neighbors=3)
neigh_clf.fit(small_X_train, small_y_train)
neigh_clf.predict(one_city.drop(columns=["country"]))
When we change our model to consider the nearest 3 neighbours, our prediction changes!
It now predicts “USA” since the majority of the 3 nearest points are “USA” cities.
Let’s use our entire training dataset and calculate our training and validation scores
cities_X_train = cities_train_df.drop(columns=['country'])
cities_y_train = cities_train_df['country']
cities_X_test = cities_test_df.drop(columns=['country'])
cities_y_test = cities_test_df['country']
kn1_model = KNeighborsClassifier(n_neighbors=1)
scores = cross_validate(kn1_model, cities_X_train, cities_y_train, cv=10, return_train_score=True)
scores_df = pd.DataFrame(scores)
scores_df
scores_df.mean()
3.11. Choosing K#
Ok, so we saw our validation and training scores for n_neighbors =1. What happens when we change that?
kn90_model = KNeighborsClassifier(n_neighbors=90)
scores_df = pd.DataFrame(cross_validate(kn90_model, cities_X_train, cities_y_train, cv=10, return_train_score=True))
scores_df
scores_df.mean()
Comparing this with the results of n_neighbors=1 we see that we went from overfitting to underfitting.
Let’s look at the decision boundaries now.
plot_knn_decision_boundaries(cities_X_train, cities_y_train, k_values=[1, 90])
If we plot these two models with \(k=1\) on the left and \(k=90\) on the right.
The left plot shows a much more complex model where it is much more specific and attempts to get every example correct.
The plot on right is plotting a simpler model and we can see more training examples are being predicted incorrectly.
3.11.1. How to choose \(K\) (n_neighbors)?#
So we saw the model was overfitting with \(k\)=1 and when \(k\)=90, the model was underfitting.
So, the question is how do we pick \(k\)?
Since \(k\) is a hyperparameter (
n_neighborsinsklearn), we can use hyperparameter optimization to choose \(k\).
Here we are looping over different values of \(k\) and performing cross-validation on each one.
results_dict = {"n_neighbors": list(), "mean_train_score": list(), "mean_cv_score": list()}
for k in range(1, 50, 5):
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_validate(knn, cities_X_train, cities_y_train, cv=10, return_train_score=True)
results_dict["n_neighbors"].append(k)
results_dict["mean_cv_score"].append(np.mean(scores["test_score"]))
results_dict["mean_train_score"].append(np.mean(scores["train_score"]))
results_df = pd.DataFrame(results_dict)
results_df
plotting_source = results_df.melt(
id_vars='n_neighbors',
value_vars=['mean_train_score', 'mean_cv_score'],
var_name='score_type',
value_name='accuracy'
)
K_plot = alt.Chart(plotting_source, width=500, height=300).mark_line().encode(
alt.X('n_neighbors:Q'),
alt.Y('accuracy:Q', scale=alt.Scale(domain=[.67, 1.00])),
alt.Color('score_type:N')
).properties(title="Accuracies of n_neighbors for KNeighborsClassifier")
K_plot
Looking at this graph with k on the x-axis and accuracy on the y-axis, we can see there is a sweet spot where the gap between the validation and training scores is the lowest and cross-validation score is the highest. Here it’s when n_neighbors is 11.
How do I know it’s 11? Here’s how!
results_df.sort_values("mean_cv_score", ascending=False)
knn = KNeighborsClassifier(n_neighbors=11)
knn.fit(cities_X_train, cities_y_train);
print("Test accuracy:", round(knn.score(cities_X_test, cities_y_test), 3))
This testing accuracy even higher than the validation mean accuracy we had earlier.
3.12. Curse of Dimensionality#
\(k\) -NN usually works well when the number of dimensions is small.
In the previous module, we discussed one of the most important problems in machine learning which was overfitting. The second most important problem in machine learning is the curse of dimensionality. This refers to that datasets with many many features generally have a sparser distribution of observations within this feature space, since there are so many possible unique combinations of features. This makes it both harder to detect the same general patterns between observations in the data and easier to accidentally mistake “noise” (meaningless correlations) for general patterns.
We will talk more later about what can be done to alleviate the curse of dimensionality, but for now it is enough to know that many supervised ML algorithms, including k-NN, can perform poorly when there are too high dimensionality in the data. With enough irrelevant features, the accidental similarity between features wipes out any meaningful similarity and \(k\)-NN is no better than random guessing.
3.13. Let’s Practice#
Consider this toy dataset:
What would you predict for \(x=\begin{bmatrix} 0 & 0\end{bmatrix}\):
1. If \(k=1\)?
2. If \(k=3\)?
True or False
3. The classification of the closest neighbour to the test example always contributes the most to the prediction.
4. The n_neighbors hyperparameter must be less than the number of examples in the training set.
5. Similar to decision trees, \(k\)-NNs find a small set of good features.
6. With \(k\)-NN, setting the hyperparameter \(k\) to larger values typically increases training score.
7. \(k\)-NN may perform poorly in high-dimensional space (say, d > 100)
8. Based on the graph below, what value of n_neighbors would you choose to train your model on?
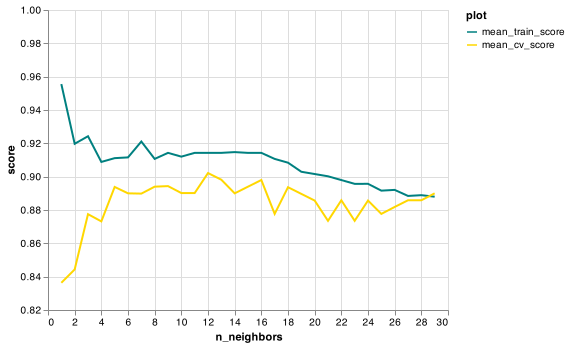
Solutions!
B
A
False
True
False
False
True
12
3.14. What We’ve Learned Today#
The concept of baseline models.
How to initiate a Dummy Classifier and Regressor.
How to measure Euclidean distance.
How the \(k\)NN algorithm works for classification.
How changing \(k\) (
n_neighbors) affects a model.What the curse of dimensionality is.